
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- HTML공부
- 정처기
- 정렬알고리즘
- 컴활1급필기
- isDisable
- 모델 훈련
- 게시판만들기
- 이것이 취업을 위한 코딩 테스트다 with 파이썬
- customized yolov5
- 데이터셋
- 방만들기
- 정처기 실기
- 글 검색
- springboot
- 객체 감지
- html
- React
- 드라이브 마운트
- thymeleaf-layout-dialect
- 데이터셋 직접
- 욕심쟁이 알고리즘
- YOLOv5
- 게시판
- labelImg
- object detection
- 조회수 증가
- 스프링부트
- combobox
- 직접 라벨링
- css
- Today
- Total
기록장
(1) - image augmentation으로 yolov5 모델 정확도 높이기 본문
우리가 모델을 훈련시키는 데 사용한 데이터셋은 두가지 종류의 사진들이었는데,


[그림 1]과 [그림 2]가 그 예시들이다.
train data 2648장, validation data 306장을 train 시킨 모델의 정확도는 꽤 높으나 실제 영상에서 사용해봤을 때 차를 잘 detect 하지 못하는 경우가 발생했다. (사람에게 가려진 차와 밤 영상에서의 차 등)
멘토님께 조언을 구한 결과, image augmentation을 시도해보기로 결정했다.
먼저 image augmentation에는 종류가 다양한데 우리는 그 중 rotation, cutout, grayscale을 사용했다.
이번 장에서는 rotation과 cutout 에 관한 이야기를 해보려한다.
1) rotation
말 그대로 아래 그림처럼 이미지를 회전 시키는 것이다. 소스 이미지를 일정 수의 각도만큼 시계 방향 또는 반시계 방향으로 회전하여 프레임 내 물체의 위치를 변경한다.

rotation을 시키는 코드는 다음과 같다.

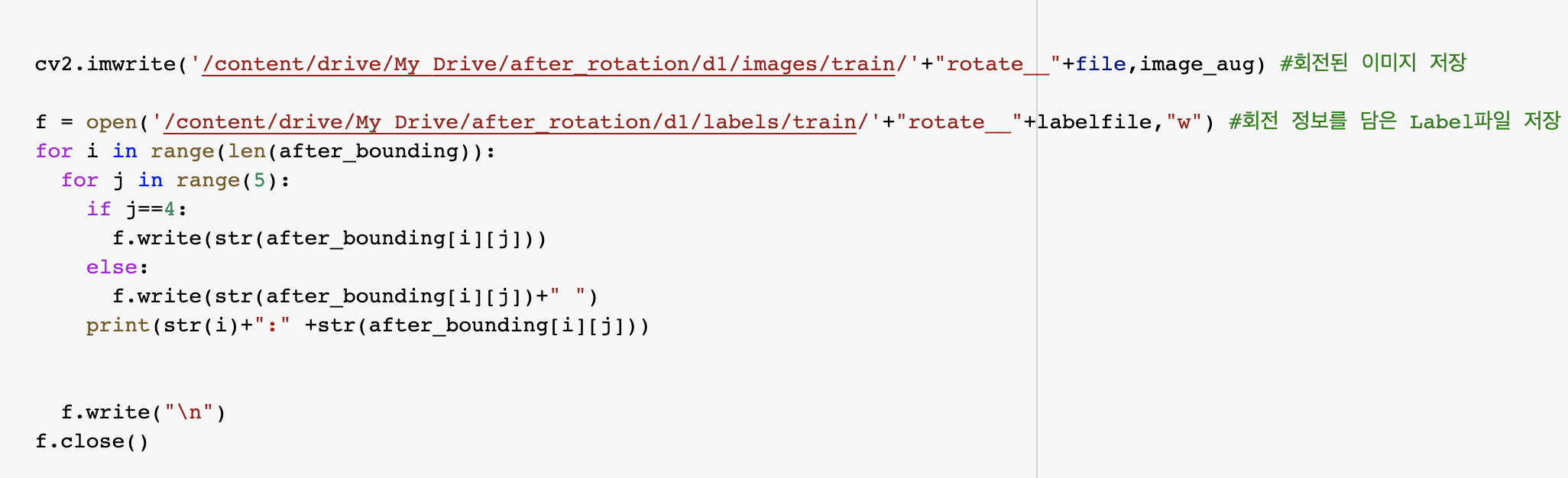
먼저 rotation을 적용시킬 이미지를 불러오고, 그 이미지의 바운딩 박스 정보를 읽어서 저장한다.
기존 바운딩박스는 [x,y, w, h] 가 저장되어 있기 때문에 x1, y1, x2, y2를 계산하여 담을 새로운 리스트를 생성한다.

rotation을 적용하는 코드 (나는 여기서 시계방향으로 20도를 회전시켰다)

rotation을 하면 객체의 위치가 변하기 때문에 label 파일의 바운딩박스의 값도 변경해서 저장해야한다.
2) cutout
컷아웃(Cutout)은 훈련 중 입력 영상의 임의 부분을 가리는 것으로 구성되는 CNN의 간단한 정규화 방법이다. 이 기법은 가려진 예를 시뮬레이션하고, 모델이 몇 가지 주요 특징의 존재에 의존하지 않고 결정을 내릴 때 더 작은 특징들을 고려하도록한다. 우리는 컷아웃을 자체적으로 코드를 만들어 수행했다. 라벨 파일의 바운딩 박스 정보를 통해 바운딩 박스의 (x1,y1,x2,y2) 좌표를 구했다. 이 좌표는 바운딩 박스의 왼쪽 위 좌표와 오른쪽 아래 좌표를 의미한다. 이 좌표를 통해 바운딩 박스 안의 임의의 섹션에 정사각형 이미지를 삽입해 cutout을 수행했다. 임의의 섹션을 정하는 과정에서는 바운딩 박스 안에서 차를 가릴 정도의 섹션 범위를 경험적으로 구했다.



cutout은 rotation과는 달리 객체의 위치가 바뀌지는 않기 때문에 bounding box의 정보는 바꿀 필요가 없다. 그래서 label 파일의 내용을 복사해서 새로 만들어주면 된다.
***추가
cutout 코드의 들여쓰기 부분이 헷갈리시는 것 같아 다시 for문 부분만 캡쳐했습니다.

#d1_train_cutout 생성 (O)
#d1_val_cutout 생성 (o)
#d3_train_cutout (o)
#d3_val_cutout
import numpy as np
from os import listdir
from random import *
import cv2
from google.colab.patches import cv2_imshow
#d1_images cutout 하기
path ='/content/drive/My Drive/before_aug/d3/images/val/' #cutout을 추가하고 싶은 이미지가 있는 경로
for file in listdir(path): #경로에 있는 파일 하나하나
cutout = cv2.imread(path+file) #사진 파일 1개 (cutout을 추가하고 싶은 원본사진)
labelfile = file.replace('.jpg','.txt')
#그 원본사진의 boundingbox 정보가 있는 label file명(저는 사진과 파일명을 똑같이 했기 때문에 jpg->txt 교체만 해줬습니다)
label = open('/content/drive/My Drive/before_aug/d3/labels/val/'+labelfile,'r') #label file을 open해서 읽는다
list=label.readline() #label 첫 줄 읽기
for i in range(3):#저는 cutout 이미지를 3개 만들고 싶어서 for문을 3번 실행시켰습니다.
f = open('/content/drive/My Drive/labels/val/'+'cutout'+str(i)+'__'+labelfile,"w") # 새로운 라벨파일 저장 (사진 1장당 1개 - 이름 맞춰서 )
while(list):#바운딩 박스 당
#print(str(i) +list)
f.write(list) #바운딩 박스 정보를 새로운 라벨 파일에 적는다.
#print(list)
list=list.split()
x_center=float(list[1])
y_center=float(list[2])
height=float(list[4])*832
width=float(list[3])*1664
x_center_new=x_center*1664
y_center_new=y_center*832
#print(x_center_new,y_center_new)
x1=uniform(x_center_new-width/2,x_center_new+width/4)
y1=uniform(y_center_new-height/2,y_center_new+height/4)
mark=width/2
x2=x1+mark
y2=y1+mark
x1=int(x1)
x2=int(x2)
y1=int(y1)
y2=int(y2)
#print(x1," ",y1," ",x2," ",y2)
cutout = cv2.rectangle(cutout, (x1, y1), (x2,y2), (0, 0, 0), cv2.FILLED) #원래 있던 사진 + 박스추가 + 박스추가 ..
list=label.readline() #다음 바운딩 박스를 위해 다음 줄을 읽는다.
f.close()
#cv2_imshow(cutout)
label = open('/content/drive/My Drive/before_aug/d3/labels/val/'+labelfile,'r')
list=label.readline()
cv2.imwrite('/content/drive/My Drive/images/val/'+'cutout'+str(i)+'__'+file,cutout)
cutout = cv2.imread(path+file)
#라벨 복사
혹시 몰라 코드도 올렸습니다 :)
'2020 졸업프로젝트 - 기술 기록용' 카테고리의 다른 글
| labelImg 라이브러리를 이용하여 데이터셋 만들기 (0) | 2021.02.15 |
|---|---|
| yolov5 를 customize해서 나만의 object detection 모델을 만들어보기 (5) | 2021.02.15 |
| (2) - image augmentation으로 yolov5 모델 정확도 높이기 (0) | 2020.11.13 |
| (1) object detection 모델(pytorch)을 안드로이드 앱에 적용해보자 ! (4) | 2020.09.17 |
| 머신러닝으로 자동차 object detection을 해보자 - (2) yolov2 tiny 모델을 COLAB에서 customize 하기 (0) | 2020.09.17 |
